今回は、趣向を変えて疫学の話です。因果推論(causal inference)で重要なDirected Acyclic Graphs (DAG)について解説したいと思います。多変量解析でmodelに入れる因子を決定するのに、とても重要なステップです。最後まで読んでいただけると、
- どのようにDAGを描くのか
- なぜパソコンの計算のみで因果推論ができないのか
- 多変量解析でどうやってモデルに入れる因子を決めたら良いのか
が理解できると思います。
では、はじめましょう。
Causal inference (因果推論)とprediction (予測)

因果推論では、ある因子(exposure)があるoutcomeに影響を及ぼしているか(effectがあるか)を推論します。例えば、ある治療薬を使うこと(exposure)でICU死亡率(outcome)にどう影響を与えるのかを調べたい、といった感じです。後述しますが、「association」ではなく「effect」を調べたいのです。
それに対し、predictionでは、あるoutcomeを予測するより良いモデルを作ることが目標になります。ICU入室時の情報を元に、入室後30日時点での死亡率を予測したい、といった感じです。その正答率を上げることが目標であり、何が何を引き起こしているかといった「effect」には興味がなく、強い「association」のある因子を見つけ、より良いモデルを作ることが大切になります。
このcausal inferenceとprediction、似ているようで異なるので注意が必要です。
例えば、ある研究でICU入室時の乳酸値は予後不良因子という結果となったとします。この研究がprediction modelであれば、死亡というアウトカムを「予測」するに際し乳酸が有用な因子であることを意味していますが、高乳酸値が死亡率を上げる(乳酸値が高いから体に悪影響があり死亡する)ことは意味していません。単に、死亡と強く関連しているだけです。
もし乳酸値が死亡率に影響するかどうか調べたければ、DAGを描いて因果推論をする必要があります。
医学論文の中には、causal inferenceとpredictionをごっちゃにしているものも見られます。
例えば、低Na血症が30日死亡率上昇と関連していた、という結果になったとしましょう。多変量解析を使い、それは「independently associated」であったとしましょう。しかし、それはあくまでassociationであってもeffectではありません。にも関わらず、論文の考察の部分で「低Naは死亡率を上昇させる」と間違えて書いてしまっている、ということです。
この、「低Na血症が30日死亡率上昇と関連していた」(association)と、「低Naは死亡率を上昇させる」(effect)は似て非なるものなので、注意が必要です。そして、このeffectを調べる(因果推論をするため)には、DAGを描くことが必要ということです。
疫学 vs. 統計学
ちなみに、疫学者と統計学者で言葉の使い方がかなり異なります。例えば、統計学者がinteraction termと一言で表していても、疫学者にとってはモデルに入れているときはproduct termと言いますし、その解釈を考えているときはeffect modificationと言います。
また、統計学者にとっては他の因子をコントロールする方法は「adjust」とまとめてしまいますが、疫学者はその調整方法をregression (stratification), propensity score, standardization, IPWなどと分け、「adjust」と言う言葉を嫌います。以下に、幾つか例を挙げました。

公衆衛生の授業や宿題でも、私は何度も疫学者に間違いを指摘されました。統計の授業や宿題では殆ど何も言われないちょっとしたことであっても、疫学者にとってはどうしても許せないことなんですよね。
因果推論のためのステップ
因果推論をするためには、大まかには以下の3つのステップを踏む必要があります。

- Expert knowledgeに基づきDAGを描く
- Identification: ここは、疫学で非常に大切な考え方になりますが、今回は割愛させてください。
- データを解析する。
これらのステップを踏むことで、effectがあるかどうかを評価できます。そして今回は、そのDAGを解説していきます。
Directed Acyclic Graphs (DAG)
DAGの由来

Causal diagramsやcausal graphsとも呼ばれるDAGですが、因果関係を矢印で表します(Directed)。
そして、diagram上で時間軸は左から右に流れますので、決して左に戻って循環しません(Acyclic)。
このDAGを描くには、expert knowledgeが必要になります。どういうことかと申しますと、例えば吸入麻酔薬で麻酔するのか、プロポフォールなどの静脈麻酔薬で麻酔するのかという決断を、麻酔科医がどのように判断しているのかは、麻酔科医にしかわからない、ということです。喫煙歴、性別、乗り物酔いの既往などがその麻酔方法の選択に影響を与える、ということを知らなければ、DAGを描けません。血液データや外科医によって麻酔方法を変えているのであれば、それらのデータも必要となります。どのような矢印を描くかの判断は、疫学者や統計学者だけではできず、臨床の場で働く医師の知識(expert knowledge)が必要ということになります。
裏を返すと、DAGは描く人それぞれで異なる可能性があります。それはそれで構いません。様々なDAGを描き、それらDAGを元に調整する因子を決めmodelを作成し、effectを計算します。DAG毎にeffectに大きな差がなければ、おそらく知りたいA→Yのeffectは真実だろうと考え、大きな差があれば何か私たちの想像外の因子があると考えDAGを再考、必要であれば追加データの収集が必要となります。
DAGの例
こちらが、最もシンプルな因果推論の例です。

まず、喫煙が肺癌を引き起こしているという矢印を描きます(assumption)。その他には喫煙や肺癌に影響を及ぼす因子がないと考えた場合、他にadjustする必要のある因子がないということなので、最後にデータを解析します。そこで両者にassociationがあるならば、喫煙が肺癌へ何らかの影響を及ぼしている(effectあり)と考えます。
3つの基本的なDAG
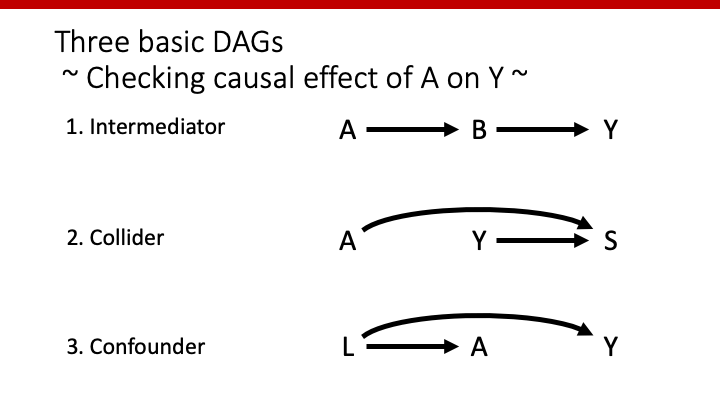
基本的なDAGとして、
- Intermediator
- Collider
- Confounder
を知っておく必要があります。逆に、この3つさえ知っておけば、臨床研究の質がグンと上がるだけでなく、疫学者と共通言語を持つことができます。是非知っておいてください。
1. Intermediator (介在因子)
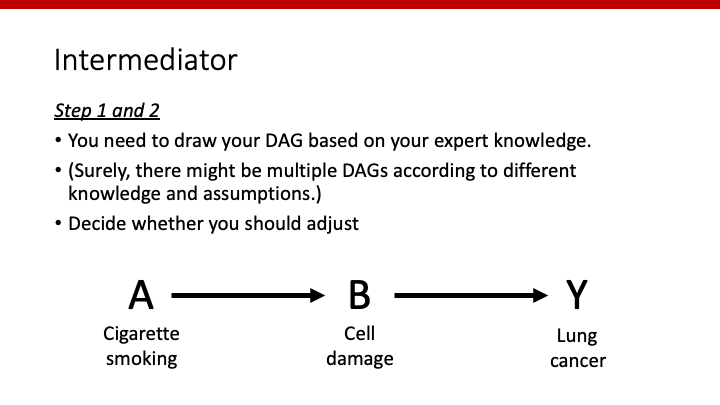
Intermediatorとは、AからYに向かうeffectの間を介在する因子のことです。例えば、喫煙が肺癌を引き起こす機序として、細胞レベルの傷害があるとします。その場合、細胞の傷害は喫煙と肺癌の介在因子(intermediator)であると言えます。このようなintermediatorがあったとしても、AとYの関係性をデータで調べると、「関連あり」となります。DAGを元にassociationありとなったため、この場合、喫煙は肺癌に影響あり、と言うことができます。
では、細胞レベルの傷害がある(orない)人のみに限定して解析するとどうなるでしょうか。このように、解析をあるグループのみに制限することを「条件付け(conditioning)」と言います。例えば、細胞傷害のある人(orない人)のみに制限して解析することを、英語でconditioning on Bやwithin levels of Bというように表現します。これは、回帰分析でその因子をmodelに入れることと同じです。
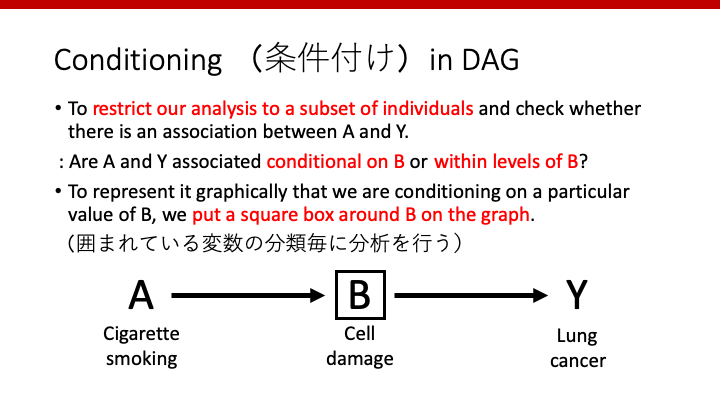
DAGでは、その因子を四角で囲むことで、条件付けを行ったことを示すことができます。
例えば、細胞レベルの傷害がある人のみを解析した場合、喫煙と肺癌の関係性はどうなるでしょうか。(喫煙から肺癌へのpathwayが細胞傷害以外にない場合)肺癌の原因はあくまで細胞傷害であるため、細胞傷害がある人だけを対象とした場合、もはや喫煙の有無と肺癌の有無に関係性は無くなります。すなわち、「no conditional association」や「independent conditional on B」と表現します。(もちろん、細胞傷害がない人のみを解析した場合も、喫煙と肺癌の関係性はなくなります。)
もし今の説明を聞いて「いや。細胞傷害の有無と肺癌との関係は、喫煙があるかないかによって異なるはずだ」と思った人がいるかもしれません。しかし、それは疫学的にはeffect modification(細胞傷害が肺癌に及ぼす影響が、喫煙の有無によって変わる)と表現し、全く別の概念となります。
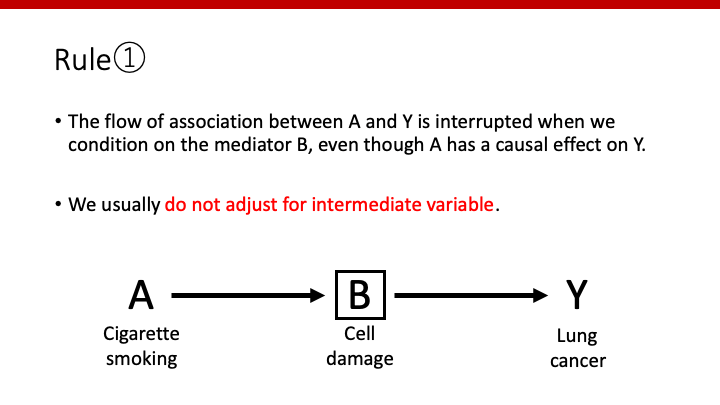
Rule ①
AからYへのflowはintermediatorで条件付けることによってブロックされ、関係が失われる。
Intermediatorで調整してはならない(回帰分析のmodelに入れてはならない)。
2. Collider

次は、上のようなケースを考えてみます。ある癌の原因として、遺伝因子と環境因子があるとします。この場合のDAGは、上のようになります。このように、矢印が集まるcommon effectのことをcolliderと呼びます。
この場合、遺伝因子(A)と環境因子(Y)には関係はありません(もちろん、effectもありません)。遺伝因子があるからといって環境が変化する訳ではありません。データ上も、AとYの間には関連はありません。
もし、癌(S)で条件付けを行った場合はどうなるでしょうか。ある癌患者を対象とします。もしその人が遺伝因子を持っていなかったとしましょう。その場合、癌の原因は環境因子である可能性が高まるでしょう。すなわち、癌患者を対象とした場合、遺伝因子の有無と環境因子の有無に関連ができてしまいます(AとYに因果関係がないにも関わらず、conditional associationが生まれてしまったということです。これを、あるgroupを解析することで生まれるバイアス;selection biasと呼びます。
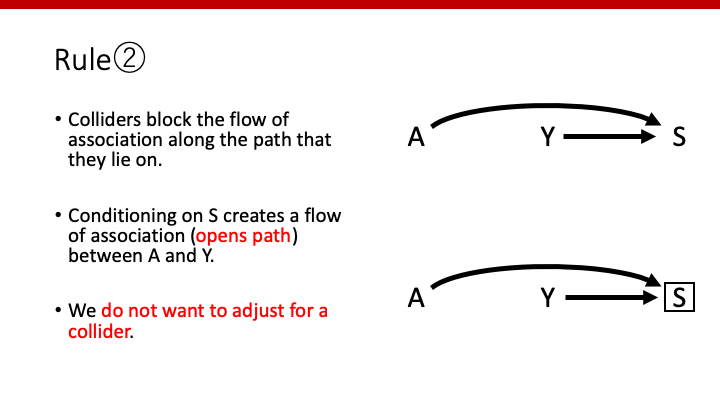
Rule ②
Colliderは、colliderを通したpathをブロックするが、colliderを条件づける(conditioning)ことによってそのpathを開き、associationが生まれてしまう。
Colliderを調整してはならない。
3. Confounder
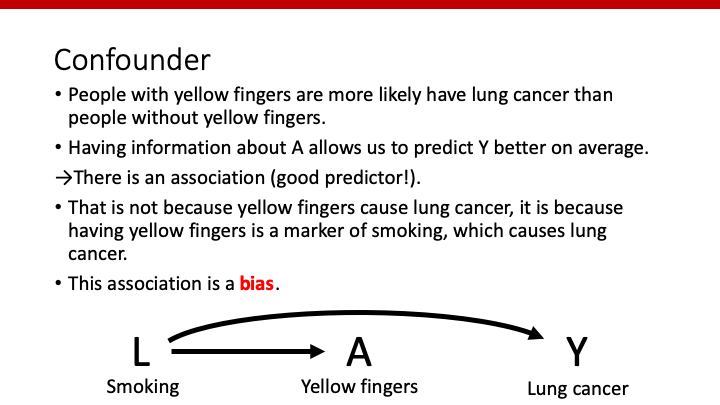
最後はconfounder(交絡因子)です。上の例では、喫煙によって指が黄色くなり、喫煙によって肺癌が引き起こされています。黄色い指であることが肺癌を引き起こしている訳ではありません。しかし、この場合、黄色い指(A)の人には肺癌(Y)である可能性が高いので、AとYの間にはassociationあり、ということになります。これも因果推論をやる上ではbiasとなるため、対処しなければなりません。
ちなみに、黄色い指であることは、肺癌を予測する上ではとても良い指標(predictor)であると言えます。Causal inferenceではなくpredictionをやるのであれば、黄色い指は強く肺癌と関連しており、重要なpredictorということになります。

このようなバイアスを除去する有効な方法が、条件付け(conditioning)です。今回であれば、喫煙群と非喫煙群に分け、黄色い指と肺癌との関連を調べる方法です。DAGで表現すると、Lを四角で囲むことになります。
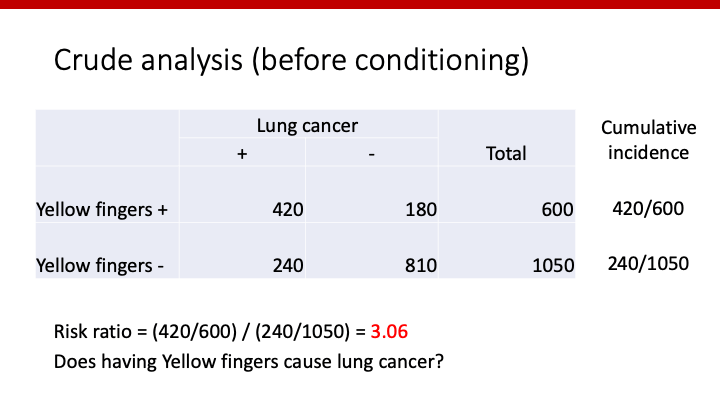
これは、数字で考えた例です。Yellow fingersと肺癌の関連は、risk ratioで考えると3.06となり、yellow findersがあった場合の方がない場合に比べ肺癌となるriskが3倍高いと言えます。しかし、果たしてyellow fingersが肺癌を引き起こしているのかを考えるのであれば、喫煙の有無で分けて解析しなければなりません。
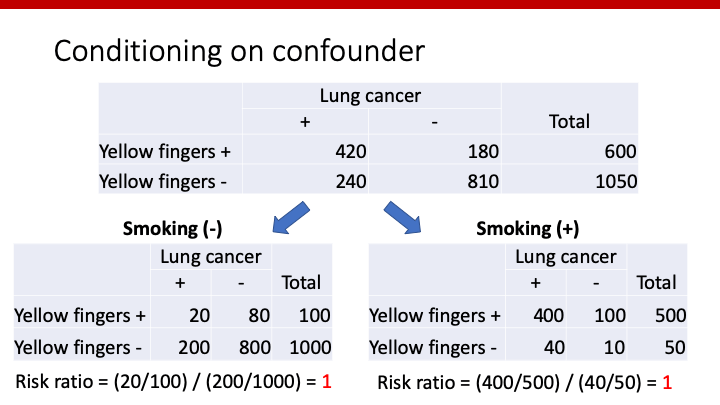
このように、喫煙の有無で分けて解析すると、どちらもrisk ratioは1となり、Yellow fingersと肺癌の関係は無しとなります。
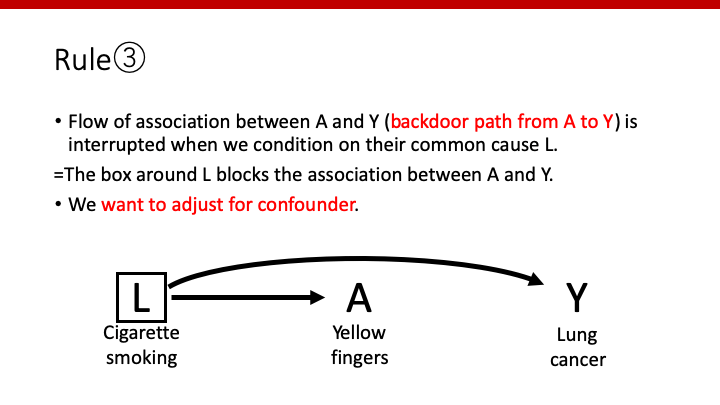
Rule③
Confounderがある場合、AとYの間にpathが開いてしまい、関連が生まれるが、そのconfounderで条件付けすることで、pathをブロックできる。
Confounderはmodel調節すべき因子である。
まとめ
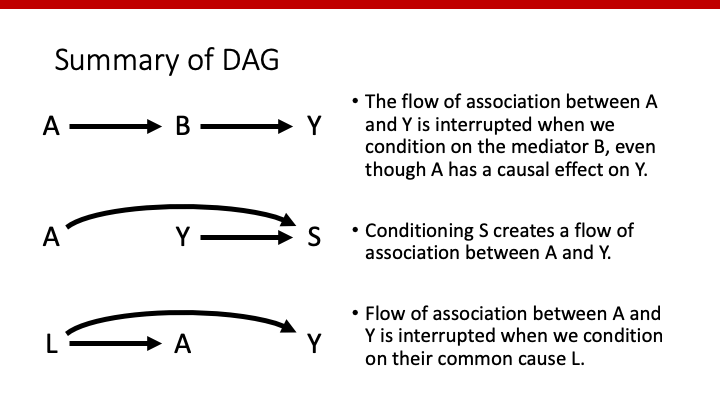
以下が、DAGの基本となるintermediator, collider, confounderのまとめになっています。AからYへのeffectを評価したい場合、intermediator (B)とcollider (S)は調整してはならず(モデルに入れてはならず)、confounder(L)は調整しなければなりません(モデルに入れなければならない)。
いかがでしたか。
DAGは因果推論の基本ですが、因果推論をしている(or したい)多くの日本人医師が教育されることのなかった分野だと思います。是非理解し、今後の研究に役立ててください。

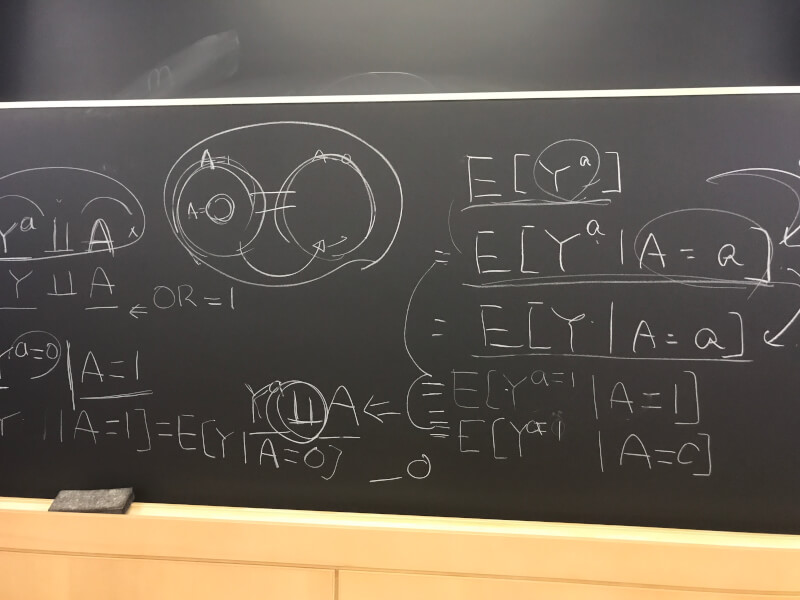


コメント
コメント一覧 (7件)
[…] この定義はかなりpopularですが、因果推論をする際には間違いを引き起こすことがあるので注意が必要です。DAGを使って説明しますので、DAGをご存知ない方はここを参照してください。 […]
[…] ちなみに、causal inferenceにしても、prediction modelにしても、exposure (or predictor)とoutcomeという、用語の使い分けが存在し、研究の目的上この両者は逆であってはなりません。 […]
[…] ちなみに、今回説明しているconfoundingは統計学のconfoundingであり、データを元に判断します。疫学のconfoundingは、データではなくDAGによって考えなければなりません。 […]
[…] “X”は、predictorやcovariateを表します。Predictorとは、outcomeとの関連性に興味のある因子のことです。因果推論においては、暴露因子ということになります。一方、covariateはpredictor以外の調整すべき因子のことです。 […]
[…] 上記のdiscussionは、主にprediction modelを作る時によく使います。因果推論(causal inference)では良いmodelを作ることが目的ではないため、このような指標はあまり使いません。Prediction modelとcausal inferenceについては、こちらをご覧ください。 […]
[…] DAGで説明したように、causal pathway上にあるintermediate variableで調整した場合、本来評価したい「X1のYに対する影響」が過小評価されてしまいます。 […]
[…] 因果推論についてはこちらを参照していただきたいのですが、簡単に言えば、因果推論とは「ある因子(exposure)があるoutcomeにどのような影響を与えるのかを評価したい」ということです。ある薬剤を使用することで患者の予後がどうなるか、ある生活習慣によって患者の発病率がどうなるか、といったものですね。患者の疾患や予後をできる限り正確に予測することを目標とした「予測モデル」とは、似て非なるものですのでご注意ください。 […]